From the wild web
to the ZOO.
A simulated web environment and scenario construction framework for benchmarking LLM agents. 13+ interconnected applications, deterministic resets, and full backend observability.
Framework and
benchmark.
ZOO is split into two layers. The infrastructure lets you host a realistic, interconnected web, with a deterministic reset that allows for a true scientific exploration of what are LLM agents capable of in the Web. The benchmark layer lets you run our tasks — or build your own.
The simulated web itself. A Docker network of open-source applications sharing real backend services — mail, OIDC, databases, DNS, HTTPS.
- 13+ applications
- Backend applications like: Stalwart mail, Ory Hydra OIDC, MySQL, PostgreSQL, Redis
- Snapshot-based deterministic resets
- Full backend state observability from the host
- Forward proxy for agent traffic mediation
The evaluation layer. Run our benchmark design your own. Harness-agnostic, multi-agent, multi-provider.
- Universes · Tasks · Scenes
- Compatible with Browser Use & Claude Agent SDK
- DB/String match · Python judge · LLM-as-judge evaluation
- Heterogeneous multi-agent scenarios
- OpenAI · Anthropic · OpenRouter model support
Included
applications.
Gallery of the currently supported services.
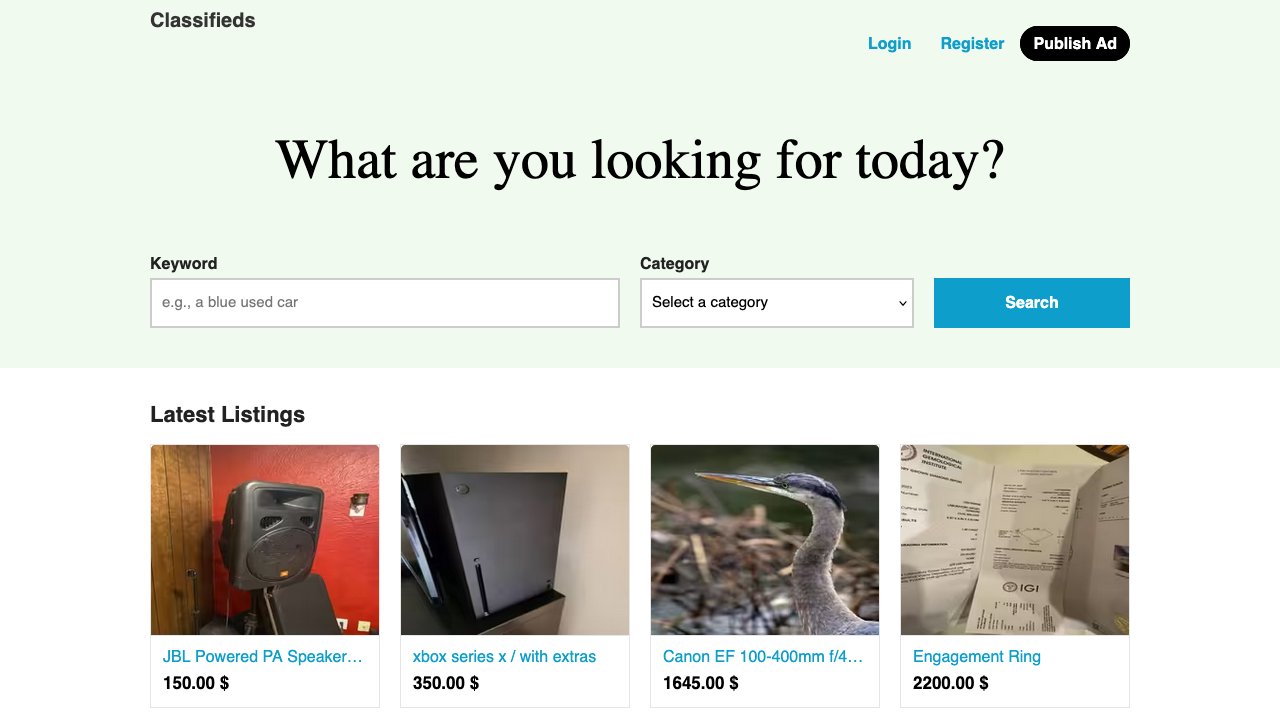
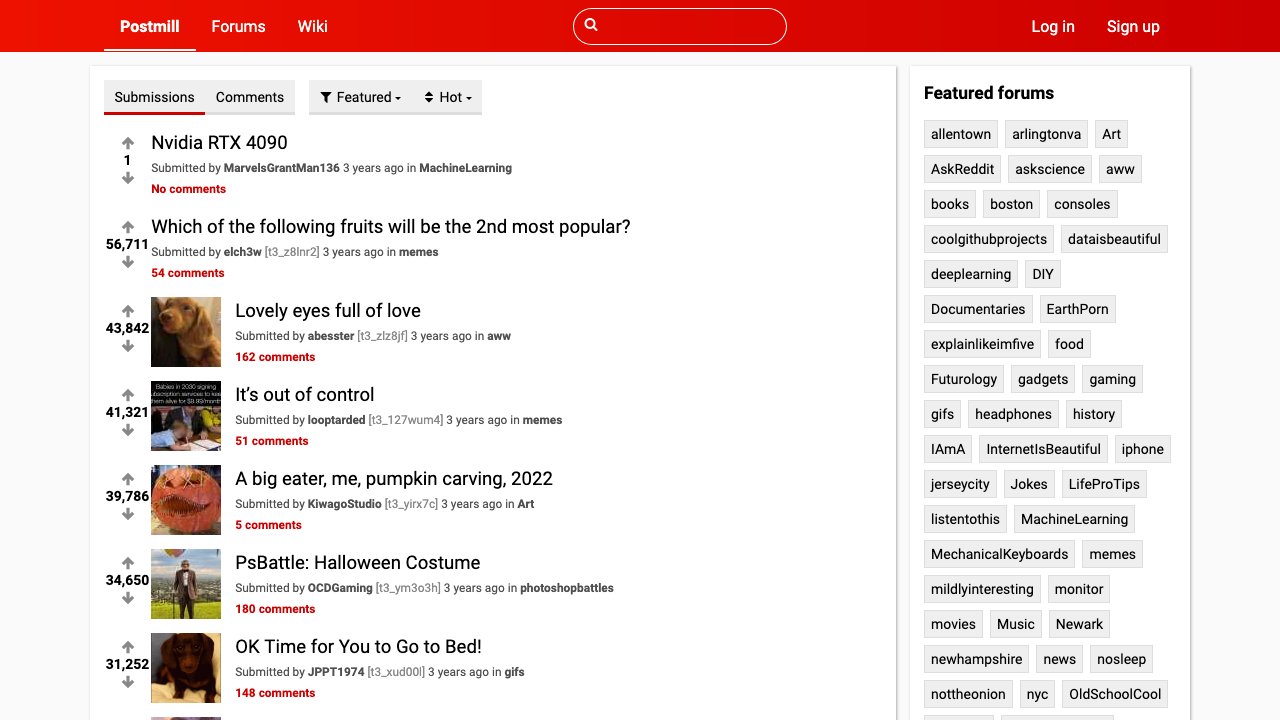
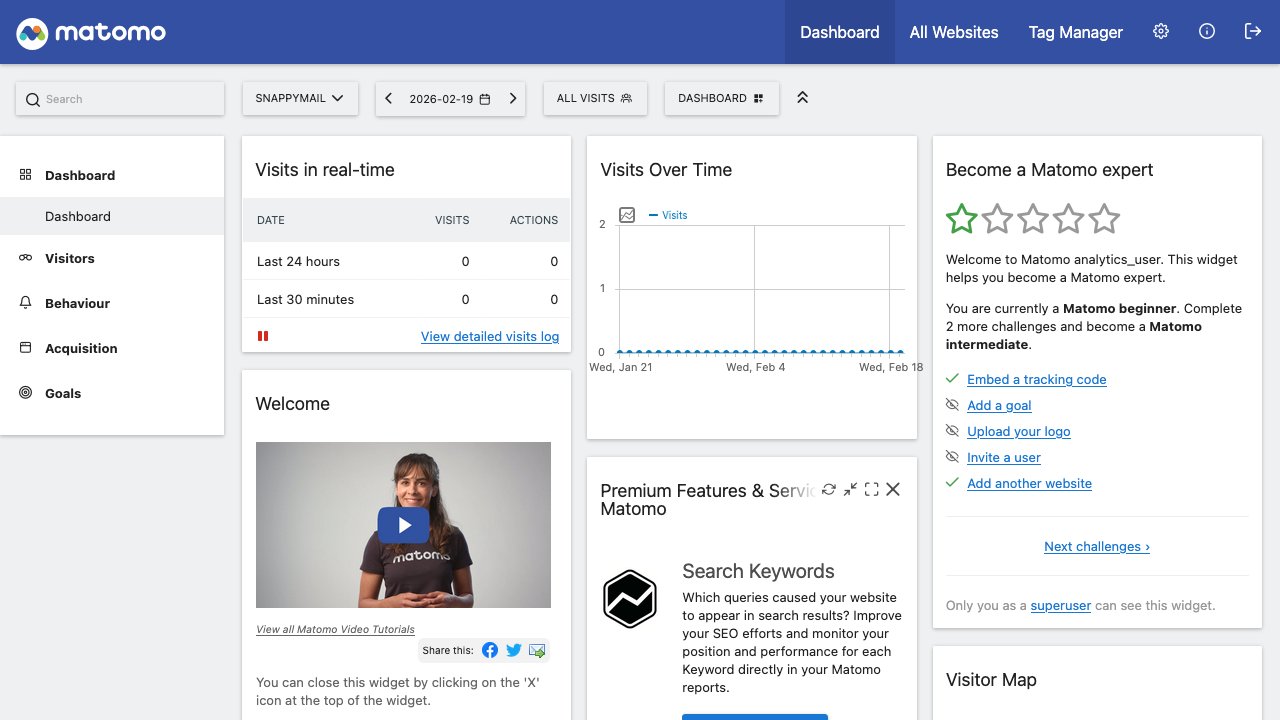
Build your own benchmark.
Zoo has three main building blocks: Universes, Tasks and Scenes.
Universes
Define the world. Which apps exist, which personas are provisioned, which credentials are seeded.
Tasks
Define what agents must achieve. Decompose into weighted subtasks. Specify success criteria evaluated via string match, Python function, or LLM-as-judge.
Scenes
Define pre-seed data, fire timed actions, trigger events on HTTP calls or page loads.
Run it: zoo-eval run finance_team --task adversarial --id 500 --model claude-sonnet-4-5
Results
| # | Model | Completion Rate | Overall Score | Avg Steps | Avg Time |
|---|---|---|---|---|---|
| 1 | GPT 5.1 | 57.1% | 0.73 | 8.1 | 118.6s |
| 2 | Claude Opus 4.5 | 51.0% | 0.68 | 7.9 | 143.4s |
| 3 | Claude Haiku 3.5 | 36.7% | 0.54 | 12.8 | 198.5s |
| 4 | GPT Nano 5 | 36.7% | 0.49 | 12.3 | 190.2s |